
機械学習の事前準備については、こちらの記事をご覧ください。
この記事では、前回の記事で準備した過去5年間分の食中毒データを使って、今後3年間の食中毒の発生状況を予測したいと思います。
使用するデータの列名を変更する
まずは、前回作成したdf_freqの列名を変更します。列名を変更するにはrenameを使います。変更したものを、新たにdfに格納します。
# 列名を変更する
df = df_freq.rename(columns={'発生月日': 'ds', '頻度': 'y'})
df.head()
列名がdsとyに変更されました。
なぜ列名を変更したかというと、これから使うProphetという時系列分析用のライブラリは、日付列をdsに、予測する列をyにしなければならないからです。
Prophetは、Meta(旧Facebook)が開発した時系列データの予測ライブラリです。本来、時系列データを使った予測は、難しい統計の知識が必要です。しかし、Prophetを使えば、統計の知識がなくても、デフォルトの設定のまま、いい感じの予測ができます。
過去のデータを学習する
それではProphetを使った将来3年間の予測を行っていきます。
まずは今回使用するProphetのライブラリをインポートします。
#ライブラリのインポート
from prophet import Prophet 次に、予測をする前の準備として「学習」をします。
m = Prophet() #Prophetを使うぞ!という宣言
m.fit(df) #dfの情報を学習1行目のm = Prophet()は、Pythonでは「インスタンス」と呼ばれます。簡単に言うと、「Prophetをこれから使います!」と宣言することで、Prophetが実体化し、使用できるようになります。ここでは、実体化したProphetをmに格納しています。
2行目のm.fit(df)で、dfの過去5年間分のデータをmに学習させています。学習にはfitを使います。

たった1行のコードで学習してくれるので楽ですね。
予測した結果を入れる箱を用意
まず、予測した結果を入れる箱を用意します。
future = m.make_future_dataframe(periods=1096) #予測した結果を入れる箱を用意2023年から2025年までの3年間を予測する場合、365日×3年+1日(うるう年)で1,096日になります。
このperiods=1096の数値を変えれば、その期間を予測できます。例えば10年間分を予測したければ、3,653日(うるう年が3回の場合)とすれば大丈夫です。
結果をfutureに入れました。futureの中身を見てみましょう。
future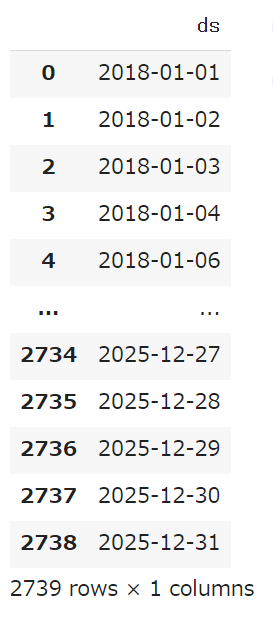
日付だけのデータですね。2018年1月1日から始まって、2025年12月31日まであります。
まずはこのように予測する期間の箱を用意します。
予測する
次のコードで実際の予測を行います。
forecast = m.predict(future) #学習したmを使って、2023年から3年間分予測するpredictを使い、たった1行で予測が行えます。結果をforecastに格納しました。
forecastの中身を見てみましょう。実は多くの列が作られているため、必要な列だけ 2重の角括弧で囲って選択します。dsが日付、yhatが予測値、yhat_lowerとyhat_upperは80%信頼区間です。
forecast[['ds', 'yhat', 'yhat_lower', 'yhat_upper']]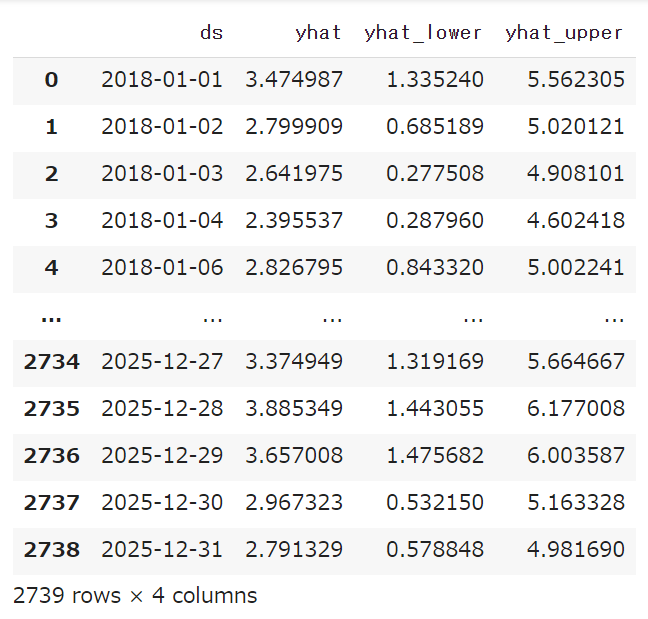
futureの箱に、2025年末までの予測結果が入っているのが分かります。このままだと、数字の羅列でわかりづらいので、続いて可視化を行います。
結果を可視化する
先ほど予測の結果を得たforecastをグラフにします。
fig1 = m.plot(forecast)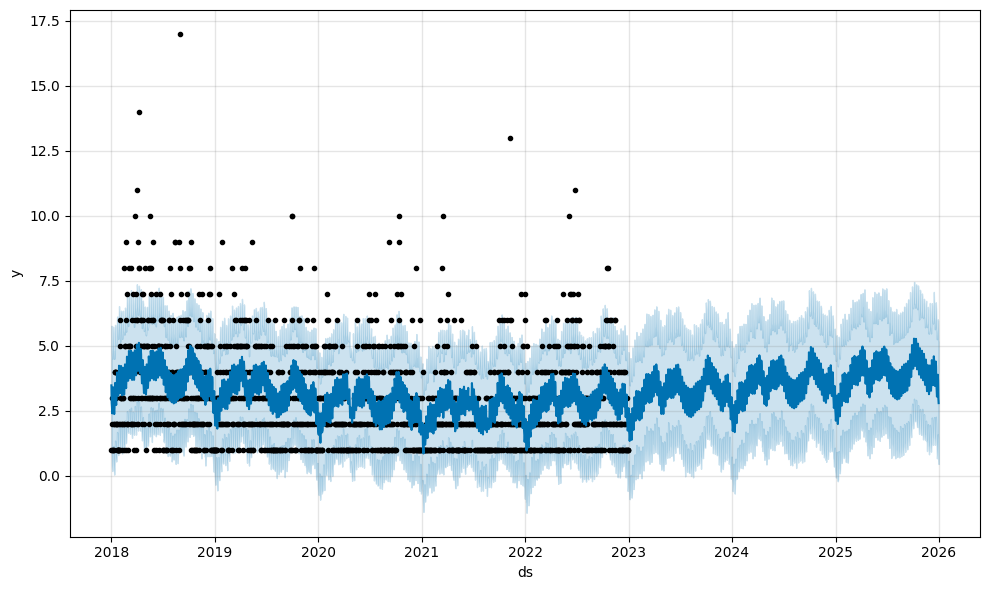
2018年から2022年末まである●は実測値です。この場合、その日の食中毒の発生件数です。2023年から●がない理由は、実測値がないためです。
🔵は予測値です。つまり、forecastのyhatの値です。
水色の区間は「80%信頼区間」です。つまり、forecastのyhat_lowerとyhat_upperの値です。
このグラフを見ていると、ジグザグしているので、何となく周期性がありそうですね。そして2023年以降は増加傾向があるように見えます。
次に、この期間の傾向と、季節性などについても見てみましょう。plot_componemtsで先程のグラフを成分ごとに分解したグラフを作成できます。
fig2 = m.plot_components(forecast)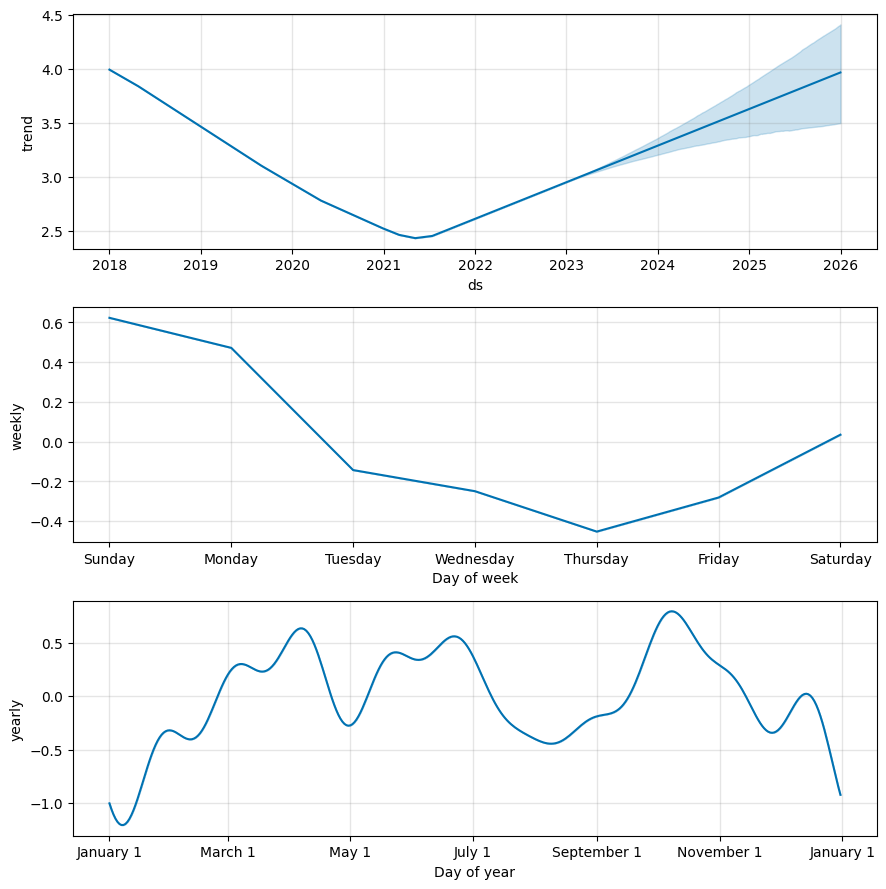
1つ目のグラフでは、この期間の傾向を見ることができます。ここ数年減少傾向にあったのが、2021年途中で底をつけた後、やはり2022年から増加傾向にあることが分かります。
増加傾向の理由は、2020~2021年あたりにCOVID-19が大流行したことが要因としてありそうです。この期間、外出・外食が減少し、食中毒発生件数が減少しました。そして2022年は自粛が徐々に緩和されていったことにより、再び食中毒が発生するようになりました。そのため、2022年の増加傾向を加味し、2023年から増加のトレンドになっているのではないかと推測されます。

2つ目のグラフでは、週の傾向を見ることができます。
日曜日に最も多く、木曜日に最も少なくなるようです。金曜日、土曜日に多くの人が外食し、その1~2日後に食中毒を発症したため、日曜日が最も多くなっているのかもしれません。しかし、元のデータの発生月日が何の日(食中毒の症状が出た日?保健所に届け出した日?原因食品を食べた日?)なのか分からないので推測になります。
3つ目のグラフでは、年間の傾向を見ることができます。
1月に最も少なく、4月と10月に多いことが分かります。食中毒の原因物質(細菌、ウイルスなど)ごとに分析しないと、この理由はわからないです。発生件数が一番多いのはアニサキスなので、もしかするとアニサキスには季節性があるのかもしれませんね。
(参考)Plotlyでインタラクティブなグラフを描画
参考までに「Plotly」というライブラリでもグラフにしてみましょう。Plotlyは簡単にインタラクティブなグラフを作成することができる、最近人気のライブラリです。
from prophet.plot import plot_plotly, plot_components_plotly
import plotly.io as pio
pio.renderers.default = "colab"
fig1 = plot_plotly(m, forecast)
fig1.show()
fig2 = plot_components_plotly(m, forecast)
fig2.show()








コメント