


このブログの記事でよく「全ゲノムシークエンス(WGS)」がでてきますが、一体何をしているのか、なぜ重要視されているのか、いまいちピンときません。専門家でなくても知っておくべきことを教えてください。
このブログでもよく「全ゲノムシークエンス」(Whole Genome Sequence:WGS)という言葉が出てきます。
そのため、「WGSは、従来の方法と比べて解像度が高い。」とか、「アメリカの食中毒調査ではルーチン的に用いられている。」といったことはすでにご存じかもしれません。
でも、それだけでは漠然としていますよね。

実は「WGS」は行政機関だけでなく、食品企業でも「汚染の原因究明」や「工場の衛生管理」に活用され始めています。そのため、今後食品安全の担当者として、WGSに関する知識はますます重要になってきます。

それでは、皆さんは「WGS」について、どれくらい理解していますか。
おそらくこのブログをご覧になっている方の大半は、検査の専門家ではなく、現場や実務で食品安全に関わっている人だと思います。
そこでこの記事では、「検査の専門家ではない人でも知っておくべきWGSの基礎知識」を紹介します。
少し長いですが、この記事を読み終える頃には、WGSのイメージが理解でき、同僚や上司にも説明できるようになっているはずです。

WGSを知らない方は、まず下の記事を読んでいただくと、より理解が深まります。

サルモネラのサブタイピング法の概要
今回参考にした論文は「Assessment and Comparison of Molecular Subtyping and Characterization Methods for Salmonella」です。
※ Frontiers Microbiology. July 2019. Volume 10. Article 1591
2019年と少し古いですが、基本となる考え方は今でも参考になります。
この論文では「サルモネラ」を例に、菌の「サブタイピング」の方法を比較しています。
タイピングとは、細菌を種類ごとに分類することです。食中毒の原因を調べる際、まず「これはサルモネラ」「これは腸管出血性大腸菌」といったように「病原菌の種類」を特定します。これがタイピングです。
しかし「サルモネラ」と言っても、その中には食中毒を引き起こすものから毒性の弱いものまで、多くの種類が存在します。そのため、「サルモネラ」をさらに細かく分類する必要があります。これがサブタイピングです。「人間」という大きな分類の中に、「日本人」「アメリカ人」といったより詳細な分類があるのと同じようなイメージです。
サブ(sub-)には「下位の」「より細かい」という意味があります。
WGSをよく理解するには、WGS以前に使われていたサブタイピングの方法についても知っておく必要があります。
それぞれの方法を比較した概要は下のようになっています。
| サブタイピングの方法 | 使い始められた時期 | 解像度(サブタイプを識別する能力) | 結果が得られるまでの時間(単一コロニーから) | 検査機関で結果が得られるまでの時間 | 1検体あたりの試薬コスト(機器及び人件費は含まず) | 検査機関での1検体あたりの費用 |
|---|---|---|---|---|---|---|
| 血清型別 | 1934年 | 非常に低い | 2〜17日 | 2~4週間 | $5~65 | ~$175 |
| PFGE | 1984年 | 高い | 4〜6日 | 2~3週間 | $7~50 | $130~200 |
| MLVA | 2000年 | 高い | 1〜2日 | 不明 | $9~36 | 不明 |
| MLST | 2002年 | PFGEやWGSより劣る | 1〜2日 | 2~3日 | $30~82 | ~$280 |
| WGS | 2009年 | 最も高い | 3〜17日 | 2~8週 | $60~230 | $100〜$500以上 |

WGSは検査にかかる時間も費用も、劇的に高いわけではないのですね。
それでは、それぞれの方法について見ていきましょう。
ここでは科学的な正確性よりも、サブタイピング法のイメージをつかめるように紹介していきます。
それぞれの方法のイメージを理解することで、WGSの記事を読む際に理解が深まります。
血清型別法
血清型別法は、80年以上にわたりサルモネラの分類法として使われてきた方法です。
この方法では、サルモネラの菌体表面にある「O抗原」と、サルモネラが動き回るために使う「鞭毛」にある「H抗原」という2種類の抗原の組み合わせによって、サルモネラをさらに細かく分類します。
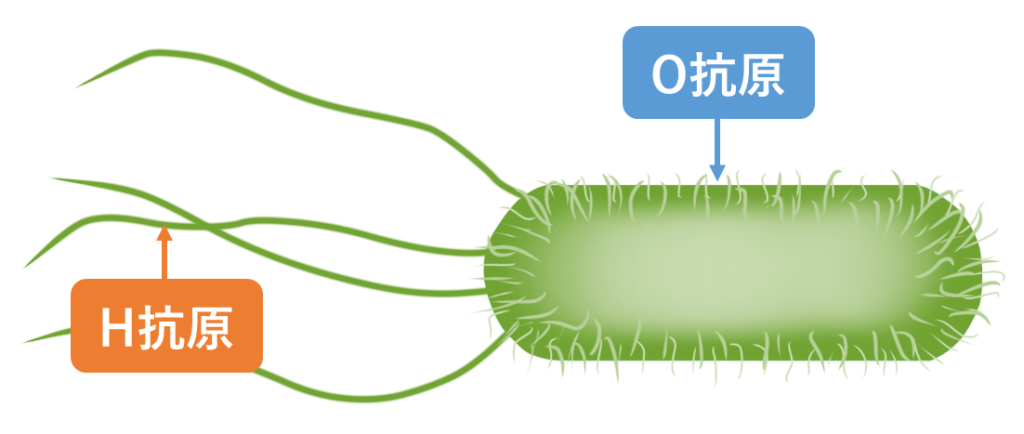
たとえば「O抗原が9、H抗原がg,m」という組み合わせのサルモネラは「Salmonella Enteritidis」とになり、「O抗原が4、H抗原がi」という組み合わせは「Salmonella Typhimurium」になるイメージです。
この方法により2,500以上の血清型が特定されていますが、ヒトの感染症の大部分を占めるのは、そのうち100未満の血清型です。

古くから使われている方法なのですね。血清型別法にはどのようなデメリットがあるのですか。
【血清型別法の課題】
- 手間と時間:サルモネラの血清型は非常に多いため、数百種類の血清を準備する必要があり、複雑な血清型の場合は検査に長い日数(12日以上)かかることもあります。
- 技術者の熟練度:正確な検査を行うためには、十分に訓練された経験豊富な技術者が必要です。
- 識別能力の限界:識別能力が低いため、関連性のない2つの菌を関連性があると誤って判断してしまう恐れがあります。例えば、「Salmonella Enteritidis」が複数の患者から検出されたからといって、これらの患者全員が同じ食品を原因とする食中毒患者とは言えません。
これらの課題を克服するため、より迅速で識別能力の高いサブタイピング法が開発されました。
パルスフィールドゲル電気泳動法(PFGE)
パルスフィールドゲル電気泳動法(Pulsed-field gel electrophoresis:PFGE)は1990年代から広く使われているサルモネラの分類法です。
この方法はサルモネラのDNAを分析することで、菌を高い精度で識別でき、「血清型別法」や後で説明する「MLST」よりも高い識別能力を持つことが証明されています。
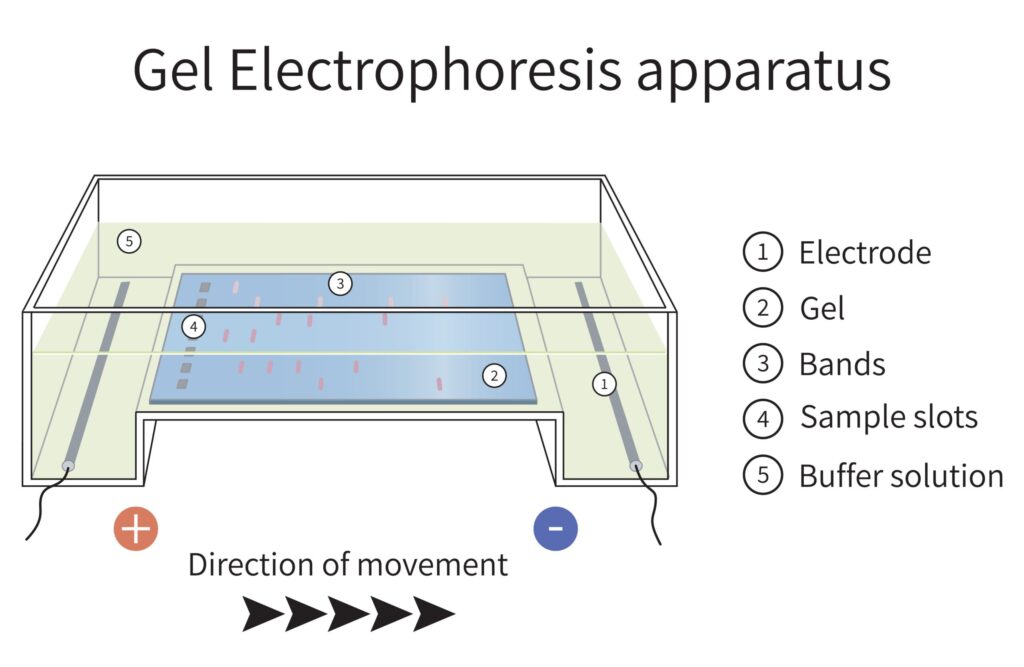
手順は以下のようになります。具体的な手順については動画をご覧ください。
- DNAを「ハサミ」で切る: サルモネラからDNAを取り出し、「制限酵素」という特殊なハサミのような酵素を使ってDNAを切断します。この酵素は、特定の場所だけを切るため、菌の種類によってさまざまな長さのDNA断片ができます。
- DNA断片を電気で並べる: これらのDNA断片をゲル(寒天のようなもの)の中に入れ、電気を流します。このとき、電気の向きを絶えず変える(パルスフィールド)ことで、DNA断片は長いものと短いものにきれいに分かれて並びます。
- DNA断片の並び方を比較する: 最後に、ゲルの上に現れたDNA断片(バンド)の並び方を画像化し、他の菌のものと比較します。このパターンが一致すれば、同じ感染源由来の菌である可能性が高いと判断できます。
しかし、長年使われてきたPFGEにも、いくつかの弱点があります。
【PFGEの課題】
- 高い専門性: 正確な分析には、高い専門技術と経験が必要です。わずかな条件の違いで結果がずれることがあるため、自動化が難しく、一度に多くの検体を処理するのが得意ではありません。
- 遺伝子情報の欠如: PFGEはDNA断片のサイズを比較するだけであり、血清型や病原性、薬剤耐性といった遺伝子の具体的な情報を知ることはできません。
- 識別の誤り:
- 小さいDNA断片やサイズの差が5〜10%未満のバンドを区別することが困難です。
- 同じサイズのバンドに見えても、DNAの配列が異なっていたり、ごく小さな突然変異により複数のバンドに変化が生じることがあります。そのため、非常に似たバンドパターンを持つ菌であっても、関連がない場合があります。逆にバンドパターンが異なっていても、関連がある場合があります。
- 遺伝的に均一なサルモネラ(例:Salmonella Enteritidis)の場合、この方法の有用性は限られてしまいます。
反復配列多型解析法 (MLVA)
MLVAは、サルモネラの種類を大まかに分ける血清型別やPFGEといった既存の方法を補完する目的で使われます。
特に、Salmonella Enteritidisのように、遺伝子の違いが少なく、従来の検査では区別が難しい株をさらに細かく分類するのに役立ちます。

MLVAは、菌が持つDNAの特定の場所にある「短い配列の繰り返し」の数を調べる方法です。
例えば、サルモネラのDNAの中に「あいうえお」という文字の塊が、何度も繰り返されている部分があるとします。

- ある菌は「あいうえお、あいうえお」と2回繰り返している。
- 別の菌は「あいうえお、あいうえお、あいうえお」と3回繰り返している。
- さらに別の菌は「あいうえお」と1回しか繰り返していない。
この繰り返しの数は、菌の種類などによって異なります。そして、この「繰り返し」について、菌の遺伝子の中にある一箇所だけではなく、複数の場所で数えます。
たとえば、以下の場合、同じSalmonella Enteritidisであっても異なる株であると言えます。
- Salmonella Enteritidisで場所Aでは2回、場所Bでは4回、場所Cでは3回繰り返している株
- Salmonella Enteritidisで場所Aでは2回、場所Bでは4回、場所Cでは5回繰り返している株
繰り返し数を比較することで、同じSalmonella Enteritidisでも、区別することができるのですね。
MLVAのメリット・デメリット
MLVAのメリットとしては次のようなものがあります。
- 速く、安く、簡単:MLVAはPCRとキャピラリー電気泳動という比較的簡単な2つのステップで行えるため、時間や費用、手間を抑えられます。
- 自動化が可能:ロボットや解析ソフトを使えば、作業を自動化でき、効率が大幅に上がります。
- 高い再現性:「Salmonella Enteritidis」などの主要な血清型については、世界共通の標準的な検査方法が確立されています。そのため、どの研究室で検査しても同じ結果が得られ、データの比較がしやすいのが大きな利点です。
一方でデメリットとしては次のようなものがあります。
- 事前の血清型特定が必要:MLVAは、調べるサルモネラの血清型ごとに異なる検査方法を用いる必要があります。そのため、MLVAを行う前に、まず菌がどの血清型に属するかを特定しなければなりません。
- 長期的な調査には不向き:MLVAの対象となるDNAの繰り返し部分は、遺伝的に変化しやすいため、時間が経つと菌株同士の関係性が曖昧になることがあります。したがって、長期間にわたる食中毒調査にはあまり適していません。
MLST(Multilocus sequence typing)
MLSTは、特に変化が少ない「ハウスキーピング遺伝子」と呼ばれる、菌が生きていくために不可欠な特定の遺伝子のDNA配列を読み取り、その違いを調べます。
分かりづらいので、人間の家系図に例えて手順をみてみましょう。
- 材料となる遺伝子を選ぶ:サルモネラにはたくさんの遺伝子がありますが、MLSTでは、菌が生きていくために不可欠な、あまり変化しない7つの特定の遺伝子(ハウスキーピング遺伝子)を選びます。これは、家系図を作るために、全員が持っている「目の色」や「髪の毛の色」など、基本的な7つの特徴を選ぶようなものです。サルモネラ菌の場合、
aroC、dnaN、hemD、hisD、thrA、sucA、purEという7つの遺伝子が選ばれます。 - 遺伝子のパターンを調べる:次に、選んだ7つの遺伝子それぞれのDNA配列(DNAの並び方)を調べます。たとえ同じ種類のサルモネラでも、このDNA配列にはわずかな違いがあります。これは、同じ家族でも、目の色が「茶色」や「青色」の人がいるように、それぞれの遺伝子に複数のパターンがあるということです。
- 遺伝子のパターンに番号を振る:見つかったそれぞれの遺伝子のパターンに、番号を割り振ります。
aroC遺伝子のパターンA → 1番aroC遺伝子のパターンB → 2番aroC遺伝子のパターンC → 3番aroC遺伝子のパターンD → 4番 …といったように、7つの遺伝子すべてに対して番号をつけます。
- 「個人識別番号」を作る:最後に、7つの遺伝子それぞれに割り振られた番号を組み合わせて、そのサルモネラ独自の「個人識別番号」を作ります。たとえば、
aroCが1番dnaNが10番hemDが5番hisDが8番thrAが2番sucAが1番purEが4番
この「シーケンスタイプ」が同じサルモネラは、遺伝的に非常に近い親戚関係にあると考えられます。一方、異なるシーケンスタイプを持つ菌は、より遠い親戚関係です。
MLSTのメリット・デメリット
MLSTのメリットとしては下のようなものがあります。
- 迅速: PFGEなどの他の方法に比べて、早く結果が出せます。
- 汎用性: 世界中で使われている共通のデータベースと解析システムがあるため、どの研究室で分析しても同じ結果が得やすく、情報の共有が簡単です。
一方、デメリットとしては識別能力の限界があります。
MLSTの弱点としては、PFGEやMLVAと比べて、同じグループ内の菌を細かく区別する能力が低いことです。
MLSTは、細菌が生きていくために不可欠で、変化しにくい7つの遺伝子(ハウスキーピング遺伝子)を調べています。
そのため、菌の間にわずかな変化(ハウスキーピング遺伝子以外の変化)が起きても、MLSTの「個人識別番号」は変わらないことがあります。
これは、家族の系図でいうと、兄弟を区別するのが難しいようなものです。
このため、食中毒の原因究明のように「どの菌が犯人か」を特定する場合には、MLSTだけでは不十分なことがあります。
全ゲノムシーケンシング(WGS)
最後にようやく「全ゲノムシーケンシング」(WGS)の登場です。
WGSは、細菌のDNA全体を丸ごと読み取る技術です。人間の体と同じように、細菌もそれぞれ固有のDNAを持っています。
このDNAは、細菌の「設計図」のようなもので、その菌の持つ遺伝子情報がすべて含まれています。
WGSのメリット・デメリット
WGSはこの「設計図」を詳細に調べることで、以下のようなことができます。
- 高い識別能力:以前はPFGEやMLVAといった方法が使われていましたが、WGSはこれらの手法よりもはるかに高い精度で菌の違いを識別できます。例えば、これまでの方法では「同じタイプ」に分類されていた細菌が、WGSで調べると実は異なるタイプだったり、逆に「異なるタイプ」に分類されていたものが、実は遺伝的に非常に近かったりすることが明らかになっています。この高い識別力により、食中毒の関連性をより正確に判断できるようになりました。
- 食中毒の原因究明と感染源の特定:食中毒が発生した際、患者から検出された菌のDNAと、疑わしい食品や環境から検出された菌のDNAをWGSで比較します。遺伝情報が非常に似ていれば、両者が同じ起源を持っている可能性が高いと判断できます。これにより、感染源(例えば、特定の食品や農場)を特定し、被害拡大を防ぐことができます。
- 菌の特性を予測:WGSで細菌のゲノム全体を調べることで、その細菌が持っている特定の遺伝子から、どのような特性を持っているかを予測できます。例えば、血清型や特定の病気を引き起こす能力、抗生物質が効きにくい耐性遺伝子の有無などを事前に知ることができます。
一方デメリットとしては、以下のようなものがあります。
- 比較的高コスト:WGSのコストは下がってきていますが、それでも他の方法と比べて比較的費用がかかります。特に、食品企業などで検査する検体数が少ない場合、1件あたりのコストが高くなる傾向にあります。
- 高い専門性:WGSで得られる膨大なデータを分析するには、バイオインフォマティクスという専門知識を持つ人材や、専用の分析ツールが必要となります。さらに、これらの維持や人材確保にかかる費用も考慮に入れる必要があります。
「規模の経済性」がコストの差を生む
最初に紹介した表でWGSの1件体当たりの費用が「$100〜$500以上」となっていました。
このように大きく異なるのは、使用する機器の規模と性能の違いが主な理由です。
参考にした文献では「Illumina HiSeq Xシリーズ」を使用した場合は「100ドル」で、「Illumina MiSeq」を使用した場合は「500ドル以上」となっています。
「HiSeq Xシリーズ」は大量のサンプルを一度に、超高速で処理するために作られた巨大な機械です。初期費用は高額ですが、一度に多くのサンプルを処理することで、1検体あたりの解析にかかるコストを安く抑えることができます。そのため、大規模な研究プロジェクトや、多くの検体を扱う機関に適しています。
一方、「MiSeq」は少量のサンプルを短時間で手軽に分析できる小型の機械です。初期投資は比較的安価で、少量のサンプルを迅速に処理できるため、小回りが利く用途に適しています。しかし、その分1検体あたりのコストは高くなります。
このように、WGSのコストは、どの機器を使って、どれくらいの規模で解析を行うかによって大きく変わります。

WGSデータ解析方法の比較
WGSのデータ解析方法にはいくつかの種類があります。ここでは、代表的な3つの手法を紹介します。
- DNAの中で「1文字だけ違う場所(SNP)」を高精度で見つけて比較します。
- イメージとしては、本の文章を1文字ずつ丁寧に比較し、「誤字脱字が何個あるか」を数えるようなものです。「こんにちは」と「こんにらは」というように 1文字の違いでも見つけることができます。
- 基準となるDNAの選び方や、解析のパラメータ設定が難しいため、専門的な知識が求められます。
- 菌のDNAの中にある「遺伝子の種類」を、全ゲノムにわたって比較します。
- 先ほど説明したMLSTは7つの遺伝子でしたが、それと比べてはるかに多い、数千の遺伝子を対象にします。
- イメージとしては、本の「章ごとの内容」を比べるようなものです。例えば「第1章は同じ、第2章は違う、第3章は同じ…第2000章は同じ」というように比較します。
- 高い再現性:基準となるDNAを必要としないため、誰が解析しても同じ結果が得やすく、データの共有がしやすいです。
- wgMLSTと似ていますが、こちらはDNA全体にある遺伝子のうち、その菌が共通して持っている遺伝子(コアゲノム)だけを比較する方法です。
- イメージとしては、そのジャンルの本に共通して存在する章の内容だけを厳選して比較する方法です。
- wgMLSTよりも比較する遺伝子が少ないため、解析が速く、データベースの構築も簡単です。
- 比較する範囲が狭いため、wgMLSTに比べて少し劣りますが、それでも非常に高い識別能力を持っています。
識別能力だけ見れば hqSNP > wgMLST > cgMLST となります。しかし、「cgMLST」であっても、従来法と比較して十分に高い解像度があります。
hqSNPの説明に「基準となるDNA」という言葉が出てきましたが、どういう意味ですか。
hqSNPの「基準となるDNA」は、比較の基準となる「お手本」のDNA配列のことです。
hqSNPは、複数の菌のDNA配列をそのまま比較するのではなく、まずすべての配列を「お手本」に沿って並べ直します。このお手本があることで、バラバラなDNA配列を統一的に比較でき、どの位置に「誤字脱字」(SNP)があるかを正確に特定できるのです。
たとえば、5人の生徒のテストの答案を比較するとします。
- 基準となるDNAは、答えがすべて書かれた「正解の解答用紙」のようなものです。
- 各菌のDNA配列は、「生徒の答案」です。
「お手本」がなければ、生徒Aの答案と生徒Bの答案を直接見比べて、どこが違うかを探さなければなりません。しかし、基準となるDNA(正解の解答用紙)があれば、生徒Aも生徒Bも、その解答用紙の1問目、2問目…というように順番に答えを並べていくことができます。これにより、「10問目の答えが、生徒AはC、生徒BはAになっている」というように、違いの場所を正確に特定できるのです。
この「お手本」は、調査対象の菌に遺伝的に最も近いものを選ぶことが非常に重要です。
もし、調査対象の菌とかけ離れたお手本を選んでしまうと、多くの部分が一致せず、正確な違いを検出できなくなる可能性があります。例えば、算数のテストの答えと国語のテストの答えを比較するようなもので、意味のある比較ができません。

おわりに
この記事ではWGSの基礎知識について紹介しました。
菌を識別する能力、結果が出るまでの速さ、血清型や病原性の予測、コスト、そして実用性を総合的に評価すると、「WGS」が既存の手法の中で最も優れているというのがよくわかりました。
しかし、WGSは高いコストと専門知識を必要とするため、すべての行政機関や食品企業がすぐに導入できるわけではありません。
そのため、この記事で紹介した手法のメリット・デメリットを踏まえ、自組織の状況に最適なサブタイピング法を検討することが重要です。
また、WGSが優れた手法であるからといって、その結果だけで判断を下すことは避けるべきです。
食中毒調査や食品工場の汚染源追跡など、どのような場面においても、最終的な判断を下し、今後の食品安全対策を決める際には、疫学的な情報(いつ、どこで、誰が、どのように感染・採取したかといった情報)が絶対に不可欠です。
WGSのどれほど解像度の高いデータも、疫学的な情報と組み合わせることで初めてその結果を正しく解釈し、食品安全の向上に役立てることができます。








コメント
コメント一覧 (2件)
全ゲノムシークエンス(WGS)の専門的な内容を、図や例えを交えて初心者にもわかりやすく解説されていて、非常に勉強になりました!特に、既存のサブタイピング法と比較してWGSのメリット・デメリットが整理されている点が良いですね。今後の食品安全業務に活かしたいと思います。
記事で紹介されている全ゲノムシーケンシングは、他の手法と比べて「高い識別能力」を持つとされています。具体的に、WGSが検出できる「細菌のわずかな違い」とは、どのような遺伝子レベルの変化を指すのでしょうか。また、その「高い識別能力」が食品安全の現場でどのように活用され、従来の検査法では見つけられなかったどのような問題の解決につながったのか、もし具体的な事例があれば教えてください。