

最近AIを使って、いろいろな予測が行われているけど、
将来の食中毒の状況も予測できるのかな?
生成AI(ジェネレーティブAI)の進化がすすみ、AIが身近なものになっています。今回は、そんなAIのひとつの分野である「機械学習」を使って、将来の食中毒の発生状況を予測したいと思います。
「機械学習って難しそう」「数学や統計学は苦手なんだよね」と思われる方がいるかもしれません。
でも、難しい理論を理解しなくても、Pythonを使えば機械学習は簡単に行えます。
一度触れてみると、今までまったく未知だったものが、何となくイメージがつかめると思います。

もし本当に使えそうなツールであれば、その後に使いながら勉強していけばよいと思います。
今回は、過去5年間分の食中毒のデータを使って、将来3年間分の食中毒の発生状況を予測します。
Google Colaboratoryの準備
Pythonを使用するにあたり、Google Colaboratory(コラボラトリー)を使用します。Colaboratoryをまだ使ったことがない方は、下の記事をご覧ください。

それでは、Colaboratoryで新規のノートブックを作成してください。今回はマイドライブに将来の食中毒を予測フォルダを作り、そこにFB_analysis.ipynbという名前でノートブックを保存しています。
それでは、事前準備としてColaboratoryとマイドライブを連携します。初めて連携を行う方はこちらの記事をご覧ください。
# Google Colaboratoryとマイドライブを連携する
from google.colab import drive
drive.mount('/content/drive')# データを格納するパスを指定
PATH = '/content/drive/MyDrive/将来の食中毒を予測/'cd {PATH}以上のセルを実行すれば、マイドライブとの連携、そして使用するディレクトリの設定ができます。
次に今回使用するライブラリを事前にインポートしておきましょう。
# 今回使用するライブラリをインポートする
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from datetime import datetimedatetimeというライブラリは初めて見ますね。これは、日時のデータを扱う際によく利用されるライブラリです。
使用するデータを読み込む
まずは1年分で試してみる
今回は、厚生労働省HPの食中毒統計資料の「(3)過去の食中毒事件一覧」のデータを使用します。
2018年から2022年までの5年間分のデータを使って、未来の食中毒発生状況を予測してみましょう。
いきなり5年分まとめてやろうとすると難しく感じます。そこで、まず1年分を試しにやってみましょう。これでうまくいけば、他の年度のデータも同じようにできるはずです。
まずは、令和2年のデータだけを使ってやってみます。
それでは新たなセルに以下のコードを入力し、実行してください。
# データを読み込む
url = 'https://www.mhlw.go.jp/content/R2itiran.xlsx'
df2020 = pd.read_excel(url, skiprows = 1, usecols = 'B:J')1行目のURLは、令和2年(2020年)食中毒発生事例のエクセルデータのURLです。これをurlに代入しています。今まではデータを一度ダウンロードしてから、読み込んでいましたが、このようにURLから直接データをPythonに読み込むこともできます。
2行目のpd.read_excelというメソッドにurlをいれるだけで、データを読み込むことができます。skiprows=1で最初の1行目は飛ばして読み込む、usecols= 'B : J'で、BからJの列だけ読み込むという指示を出しています。そして、読み込んだデータをdf2020に代入しています。
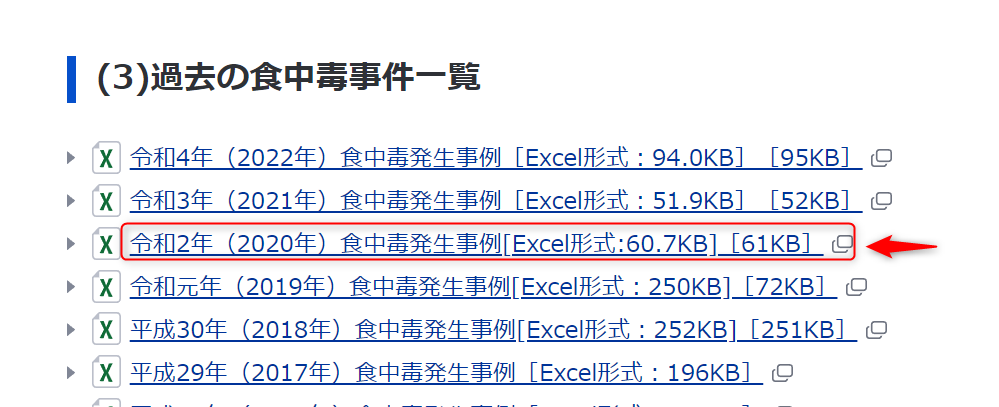
参考として、実際に厚生労働省HPからダウンロードしたエクセルデータを下に示しました。1行目は不要で、実際にデータがあるのはB列からJ列までというのが分かります。
せっかくなので、df2020の中身を見てみましょう。
df2020
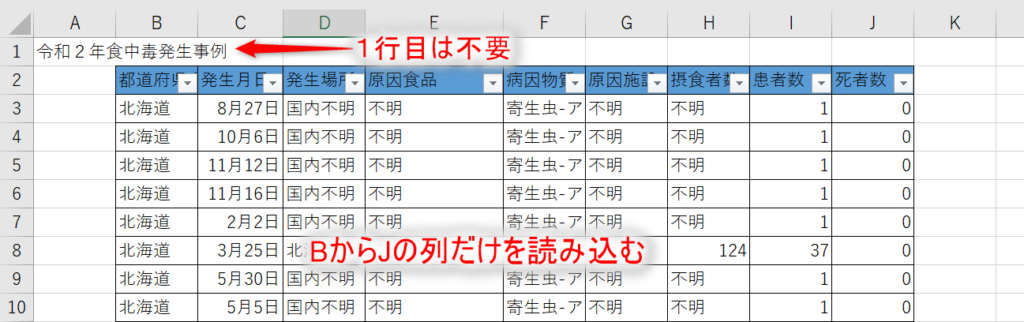
元のエクセルデータと見比べてみると、だいたい意図したとおりにデータが読み込まれています。しかし、発生月日だけは何か変です。あるセルは5桁の数字で、別のセルは「年-月-日 時間」で表されています。
5桁の数字は「シリアル値」と呼ばれ、エクセル独自の日付の管理方法のようです(参考:日経BP)。元のエクセルデータの「発生月日」のセルの書式設定が一定でないため、バラバラの形式で読み込まれてしまっています。
また、元のエクセルデータを細かく見ていくと、うるう年の「2月29日」の値が左寄りになっています。一見すると日付のようですが、文字列として扱われています。

これらの問題を解決しないと、後々エラーになります!
このようにエクセルは個々のセルに様々な修飾ができるため、データ分析する際に扱いにくいデータのフォーマットです。
日付データを正しく読み込む
文字列「2月29日」の問題は、「2月29日」を事前にシリアル値に変更しておき、その後他のシリアル値と同じように日付に変更しましょう。
ちなみに、2020年2月29日のシリアル値は「43890」になります。下のコードのreplace関数で、文字列をシリアル値に置き換えています。
# エクセルファイルに文字列で「2月29日」が含まれていたため、日付(シリアル値)に変更する
df2020 = df2020.replace('2月29日', 43890)これでうるう年の問題は解決できました。うるう年は4年に1度のため、今回使用する他の年度は気にしなくて大丈夫です。
次に、シリアル値を年月日に変更しなければならない問題です。
問題解決の一番の近道は、Google検索です。
調べてみると同じような問題に直面し、その解決方法も紹介してくれているサイトがありました。
# Excelに日付とシリアル値が混在する場合の、日付に統一する方法(参考:だもんでBlogさん)
df2020['発生月日'] = df2020['発生月日'].astype(str)
date_mask = df2020['発生月日'].str.contains('-')
df2020_excel = df2020[~date_mask].copy()
df2020_reg = df2020[date_mask].copy()
df2020_reg['発生月日'] = pd.to_datetime(df2020_reg['発生月日'])
df2020_excel['発生月日'] = pd.TimedeltaIndex(df2020_excel['発生月日'].astype(int), unit='d') + datetime(1899,12,30)
df2020['発生月日'] = pd.concat([df2020_reg['発生月日'], df2020_excel['発生月日']])このコードを実行すると問題は解決できそうです。
他の年度のエクセルファイルでも、日付とシリアル値が混在する問題はあるかもしれません。すべての年度で上と同じコードを書いてもいいのですが、5年分となるとコードの量が多くなってしまいます。そこで、今回は上のコードを使って、自分の関数を作ってみましょう。
# 自作の関数(だもんでBlogさんのコードをもとに作成)
def change_serial_num(x):
x['発生月日'] = x['発生月日'].astype(str)
date_mask = x['発生月日'].str.contains('-')
x_excel = x[~date_mask].copy()
x_reg = x[date_mask].copy()
x_reg['発生月日'] = pd.to_datetime(x_reg['発生月日'])
x_excel['発生月日'] = pd.TimedeltaIndex(x_excel['発生月日'].astype(int), unit='d') + datetime(1899,12,30)
x['発生月日'] = pd.concat([x_reg['発生月日'], x_excel['発生月日']])defはdefinition(定義)の略です。その次のchange_serial_numはこの関数の名前で、自由に決めることができます。関数の機能がわかりやすい名前を付けるとよいでしょう。
関数名の次に(x)とあります。この関数に日付に変更したいデータを入れたいので、関数名の後に括弧してx としています。実はxでなくても、なんでも大丈夫です。
その後に:があり、次の行からはインデントしています。これは、自作の関数を作る際のルールです。この関数を実行すると、インデントしている箇所が実行されます。
そのあとのコードは、先ほどdf2020で行ったコードのdf2020をxに置き換えただけです。
このように関数を作っておけば、同じコードを何度も書く必要がなくなり、作業の効率化、コードの可読性がよくなります。自作の関数について、詳しく知りたい方は「python 自作 関数」などで検索してみてください。
それではうるう年をシリアル値に変換した後に、自作関数を実行し、もう一度df2020の中身を見てみましょう。
change_serial_num(df2020) #自作の関数でシリアル値を年月日に変更する
df2020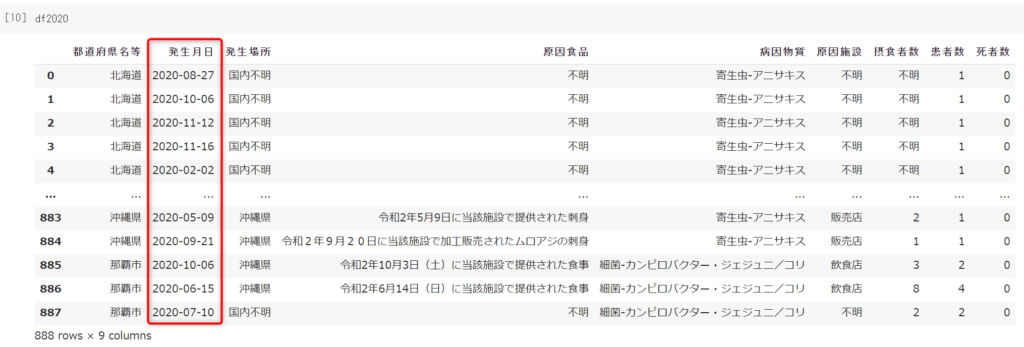
発生月日が正しく読み込まれていますね。
5年間分をまとめて行う
1つのデータでうまくいったので、これを5年間分まとめて行いましょう。
# 2022年(令和4年)のデータを読み込む
url = 'https://www.mhlw.go.jp/content/000959521.xlsx'
df2022 = pd.read_excel(url, skiprows=1, usecols='B:J')
# 2021年(令和3年)のデータを読み込む
url = 'https://www.mhlw.go.jp/content/000948376.xlsx'
df2021 = pd.read_excel(url, skiprows=1, usecols='B:J')
# 2020年(令和2年)のデータを読み込む
url = 'https://www.mhlw.go.jp/content/R2itiran.xlsx'
df2020 = pd.read_excel(url, skiprows=1, usecols='B:J')
df2020 = df2020.replace('2月29日', 43890) #文字列「2月29日」をシリアル値に変更
# 2019年(令和1年)のデータを読み込む
url = 'https://www.mhlw.go.jp/content/R1itiran.xlsx'
df2019 = pd.read_excel(url, skiprows=1, usecols='B:J')
# 2018年(平成30年)のデータを読み込む
url = 'https://www.mhlw.go.jp/content/000488270.xls'
df2018 = pd.read_excel(url, skiprows=1, usecols='B:J')
#自作関数を実行
change_serial_num(df2022)
change_serial_num(df2021)
change_serial_num(df2020)
change_serial_num(df2019)
change_serial_num(df2018)これで2018年から2022年までのデータが読み込めました。5年間分ですが、自作関数を使うことで、すっきりしたコードになりました。
データを一つにまとめる
5年間分のデータが用意できたので、これらを一つにまとめます。
# 一つのファイルにまとめる
df_concat = pd.concat([df2022, df2021, df2020, df2019, df2018], axis=0)
# 発生月日でデータをソートする
df_concat = df_concat.sort_values(by= '発生月日')concatに5年間分のデータを入れました。これで5つのデータが1つになりました。concatは「concatenate」という英単語の略で、「連結する」という意味があります。axis=0とすることで、データを縦方向に連結していきます。
次にsort_valueで、発生月日の順でデータを並べ替え(ソート)しています。
次に、頻度という新しい列を作りましょう。後ほど日付ごとの食中毒発生件数を集計するために使います。
df_concat['頻度'] = 1
df_concat
日付ごとの食中毒発生件数を計算する
事前準備の最後に、日付ごとの食中毒件数を集計しましょう。
発生月日ごとに、食中毒の件数を集計するので、「groupby関数」を使います。groupby関数についてはこちらの記事をご覧ください。
df_freq = df_concat[['発生月日', '頻度']].groupby(by = '発生月日',as_index=False).sum()
df_freq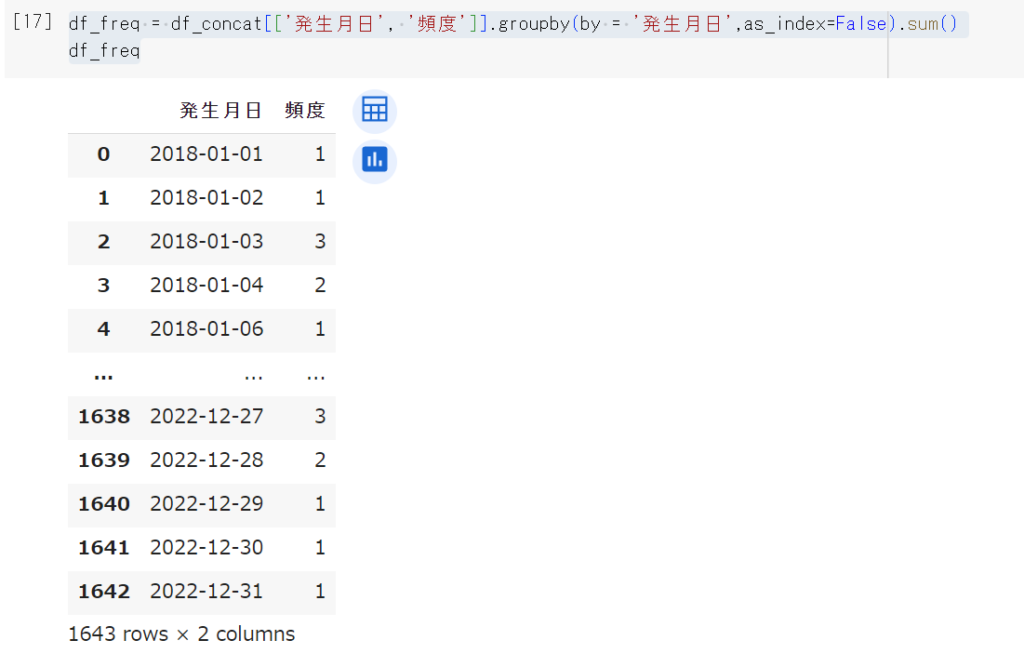
2018年1月1日から2022年12月31日までの、食中毒発生件数が集計できました。
事前準備の最後に、今集計した結果をグラフで見てみましょう。
fig, ax = plt.subplots(figsize=[10, 4]) #グラフサイズの指定
ax.bar(df_freq['発生月日'], df_freq['頻度']) #xとy軸のデータを選択
ax.set_title('Trend of Foodborne Illnesses') #グラフのタイトル
ax.set_ylabel('Frequency') #Y軸のラベル
ax.grid() #グリッド線の追加
plt.show() #グラフの表示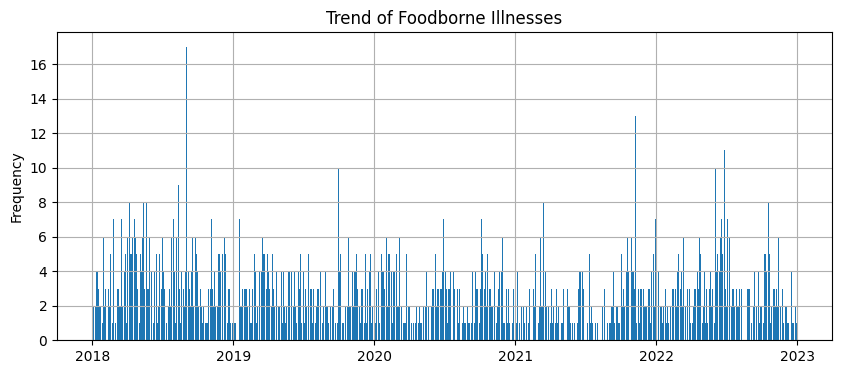
2018年から2022年末までの、食中毒発生件数のグラフができました。
2018年の途中で1日に17件も食中毒が発生した日があります。5年前ですが、何が起きたか覚えていますか?(私は全く記憶にありませんでした。)
正解はこちら
調べてみると2018年9月2日で、すしチェーン店で「輸入ウニ」を原因とする腸炎ビブリオ食中毒が複数発生したようです。
以上で機械学習を行う上での、データの事前準備になります。コードが長く、大変でしたね。

実際の分析を行うより、データの準備段階の方が、実は大変だったりします。
次の記事では、このデータを使って、将来の食中毒発生の状況を予測したいと思います。








コメント