


自社の時系列データをグラフにしたいのだけど、どうすればいいのかな。
毎日データを取っていると、データが蓄積されます。そのデータを使えば、時間、日、月、年単位で、データの傾向、周期性などを分析することができます。
「どうやって毎日のデータを分析すればいいの」や「時系列分析って難しそう」というような疑問を持っていませんか。

実はPythonを使えば、時系列データの分析を簡単に行えます。
そこでこの記事では、Pythonを使った時系列データのグラフ化を分かりやすく解説します。
使用するデータは、厚生労働省のウェブサイトに公表されている「食品の自主回収情報」を使用します。今回はこのデータを使って、
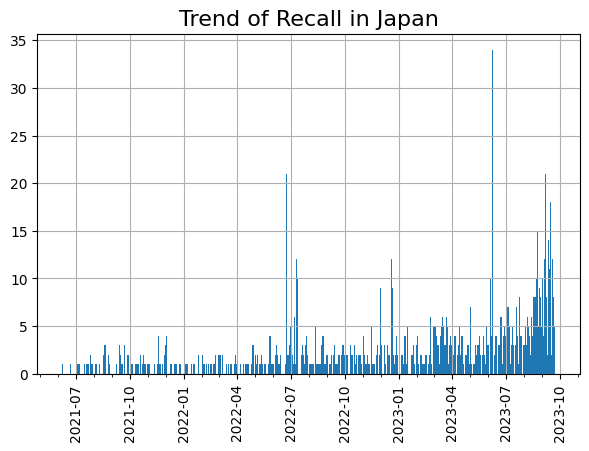
最終的には下のような時系列のグラフを作成します。
Pythonの使用環境について
この記事ではGoogle Colaboratoryを使って、Pythonでデータ分析を行います。事前の環境構築は下の記事をご覧ください。

厚生労働省のウェブサイトからデータをダウンロードする
まずは今回使用するデータを準備します。
厚生労働省の公開回収事案検索のサイトから自主回収のデータをダウンロードしましょう。
まず検索をクリックします。
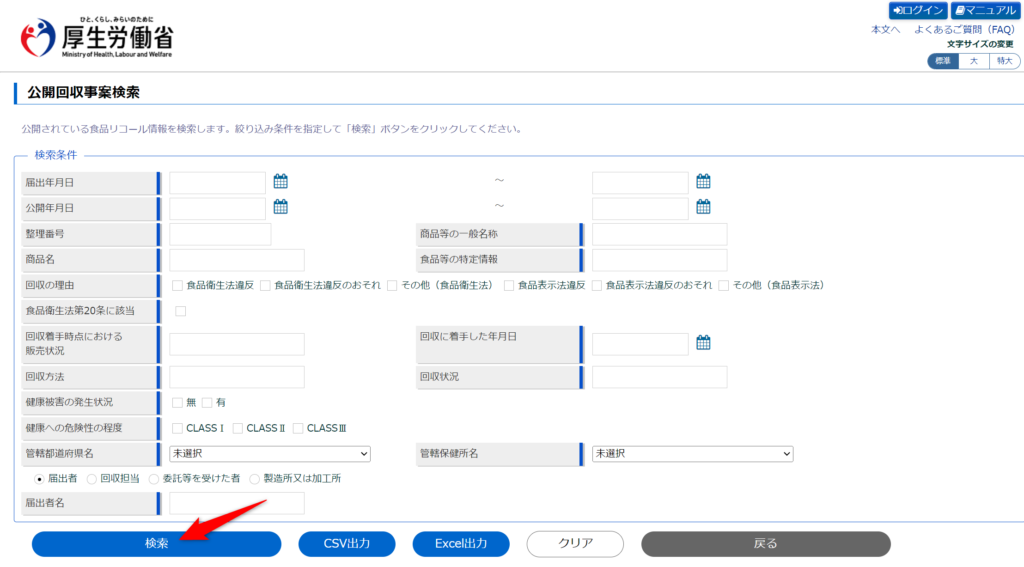
すると現在公開中の全データが表示されます。2023年9月24日AM9時の時点で1,152件の自主回収が公表されていました。
公開されている情報は、回収が終了したら2週間で削除されます(厚生労働省 FAQ「6 リコール情報」)。そのため、この1,152件は過去すべての自主回収の件数ではなく、サイトを見た時点で公開されている件数です。残念ながらすべての回収情報は見ることができないようです。
次にCSV出力をクリックします。Excel出力もできますが、今回はCSVを使用します。データ分析を行う際には、ExcelよりもCSVファイルの方が互換性、汎用性が高いため、扱いやすいです。
「公開回収事案_出力データ.csv」という名前で、データがダウンロードされました。(データがダウンロードされる場所は自分のパソコンの設定によって異なります。)
以上で必要なデータのダウンロードが完了しました。
もし同じ条件のデータで分析したい場合は、下からダウンロードしてください。zipファイルに入っているので、ダウンロード後、すべて展開し、その中にある「公開回収事案_出力データ.csv」のファイルを使用してください。
事前準備(データのアップロード、ノートブックの作成)
次にダウンロードした「公開回収事案_出力データ.csv」を自分のGoogleドライブにアップロードします。やり方についてはこちらの記事をご覧ください。
マイドライブにcsvファイルをアップロードしたら、Colaboratoryの新しいノートブックを作成します。そして、ノートブックとマイドライブを紐づけます。やり方についてはこちらの記事をご覧ください。
参考までに、事前準備のコードを下に載せておきます。ノートブック名は「recall_analysis.ipynb」としています。
# Googleドライブのファイルにマウントする
from google.colab import drive
drive.mount('/content/drive')# PATHにエクセルデータが格納されているフォルダの場所を代入する
PATH = '/content/drive/MyDrive/'# PATHを現在のディレクトリに設定する
cd {PATH}自主回収データをロードする
まずは必要となるライブラリをインポートします。
# 必要なライブラリをインポート
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import matplotlib.dates as mdates #今回新たに使用するライブラリ次にマイドライブにアップロードした「公開回収事案_出力データ.csv」を読み込みます。dfという変数に格納しています。
df = pd.read_csv('公開回収事案_出力データ.csv', parse_dates=['届出年月日']) コードの中に見慣れないparse_dates=['届出年月日']があります。これは「届出年月日」の列を日付のデータ型として読み込むように指示を出しています。
parse_dates=['届出年月日']としないと、日付データと認識されず、後々の処理でエラーになります。
ちなみに、以下のコードを実行すると、「届出年月日」のデータ型を確認できます。データ.dtypesでデータのタイプを確認できます。
df[['届出年月日']].dtypes# 結果
届出年月日 datetime64[ns]
dtype: objectdatetime64[ns]となっています。これは、届出年月日が日付のデータ型として扱われているということです。
Pythonのデータの型については以下の記事をご覧ください。

それでは、うまくdfに格納できたか確認しましょう。
df.head() #先頭5行を確認する
文字数が多いので見切れてしまっていますが、うまく格納できました。
以上で事前準備が完了です。
データの前処理をする
ここからはデータの前処理を行います。
今回の分析の最終的な目標として、届出日ごとに自主回収の件数を集計し、グラフにしてみます。
まずdfに新たに「頻度」という列を作ります。これにより件数の集計が楽に行えます。
# 新たに頻度という列を作り、そこに1を代入する
df['頻度'] = 1 次に、不要な列が多いため、必要な列(「届出年月日」と「頻度」)だけを抽出します。
さらに、届出年月日ごとに、届出件数を集計するので、groupbyを使います。groupbyについてはこちらの記事をご覧ください。
df_date = df[['届出年月日', '頻度']].groupby(by = '届出年月日',as_index=False).sum()
df_date.tail() #最後の5行だけ表示1行目のdf[['届出年月日', '頻度']]で、届出年月日と頻度の2列だけを抽出しています。それをgroupbyで届出年月日ごとにし、sumで集計しています。
groupby を使うと、by='〇〇〇' で指定した列がデフォルトで index になります(この場合「届出年月日」)。index にしたくない場合は as_index=False とします。
そして、結果をdf_dateに格納しました。
2行目では、tail関数を使って、df_dateの最後5行だけを表示しました。結果は以下のようになります。
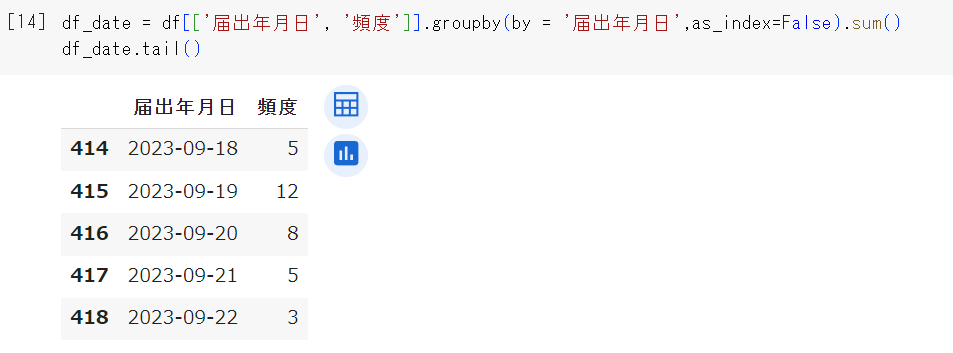
9月18日は5件、9月19日は12件の届出情報が公開されていることがわかります。
時系列グラフを書く
前処理が終わりましたので、最後に時系列グラフを書きましょう。
#自主回収の時系列グラフ
fig, ax = plt.subplots(figsize=(7,5)) #グラフのサイズを指定
ax.bar(df_date['届出年月日'], df_date['頻度']) #X軸とY軸の値を設定
plt.show()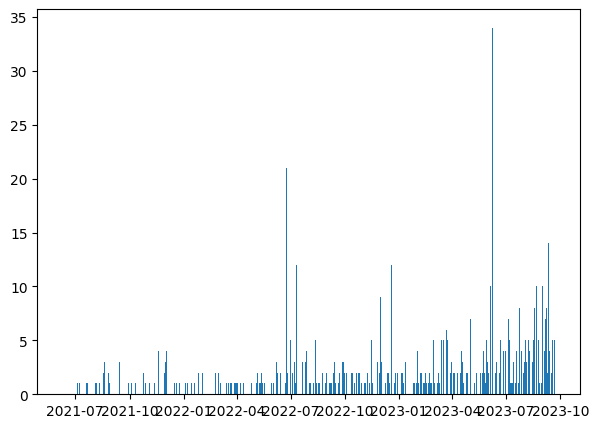
たった3行で、時系列のグラフが書けました。
でも、X軸の目盛が読みにくいですし、グラフが少し寂しいですね。
それではグラフをいろいろ修飾し、見やすくしましょう。
#時系列グラフ(修飾後)
fig, ax = plt.subplots(figsize=(7,5)) #グラフのサイズを指定
ax.set_title('Trend of Recall in Japan', fontsize=16) #グラフのタイトル
fig.autofmt_xdate(rotation=90, ha='center') #X軸のラベルを90度回転、水平位置にする
ax.grid(True) #グリッド線を追加
ax.xaxis.set_major_formatter(mdates.DateFormatter('%Y-%m')) # X目盛りの表示フォーマットを指定
ax.xaxis.set_minor_locator(mdates.MonthLocator()) # 補助目盛の設定
ax.bar(df_date['届出年月日'], df_date['頻度'], width=2) #X軸とY軸の値を設定、バーの幅を2とする
plt.show()X軸の目盛を変えただけでなく、グリッド線の追加、バーの幅の太くするなどして、グラフがより見やすくなりました。
グラフの右の方を見てみると、2023年の6月あたりに35件近くまでリコール情報が公表された日がありますね。いったい何があったのでしょうか。
また、左の方を見てみる、2021年のデータがあります。調べてみると、2021年6月9日に公表されたデータがまだ残っているようです。回収された製品の賞味期限が2年以上あるのでしょうか。
グラフにすることで新たな発見がありますね。
ただし、最初に説明したように、すべてのデータはダウンロードできないため(現在公表中のデータだけしかダウンロードできないため)、結果をあまり考察しても意味がありません。
もしすべての自主回収のデータがダウンロードできれば、より詳しい分析を行うことができます。たとえば、以下のような疑問にも答えられるかもしれません。
- 自主回収が増加する月、日、曜日はあるのか。
- 回収理由(異物混入、カビ、アレルギー物質など)に季節性はあるのか。
- 回収至った原因(表示の貼り間違い、不適切な温度管理など)の多い順番が分かれば、自分の施設でも気を付ける優先順位付けができるかもしれない。
- 「1つの店舗だけの回収」 v.s. 「複数の自治体にまたがる広域の回収」はどちらが多いのか。
- 回収される食品の種類と回収理由に関係性はあるのか。などなど

以上が時系列データを使った分析の入門編です。
みなさんの施設でも、日々蓄積された時系列のデータがあると思います。
時系列データを分析するメリットとして、季節性、周期性などのパターンを見つけ、それに基づいて対策を取ることができます。ぜひ挑戦してみてください。







コメント