
食中毒のデータを分析する(事前準備)については、以下の記事を読んでください。


今回は前回準備したデータを実際にPythonで分析します。
今までの記事で、Pythonの基礎を学んできました。ここからは、実際のデータを使ってデータ分析を行います。
食中毒データをロードする
まずは必要となるライブラリをインポートします。下のコードを1つのセルに入力してください。
# 使用するライブラリをインポートする
import pandas as pd
import numpy as np
import matplotlib.pyplot as pltpandas、numpy、matplotlibはデータの処理と可視化に使用するライブラリです。データ分析を行う際には、この3点セットをインポートしておくと間違いないです。
# 使用するデータをdfに読み込む
df = pd.read_excel('NationalOutbreakPublicDataTool.xlsx')
df.shape# 結果
(7908, 21)pandasのread_excel関数を使って、前回マイドライブにダウンロードした「NationalOutbreakPublicDataTool.xlsx」を読み込み、dfに格納しています。
shape関数はデータフレームの行数と列数を表示します。このデータは7908行、21列ありますね。
データの中身を確認する
せっかくですので、dfの中身を見てみましょう。7908行もあるので、最初の5行だけを確認してみます。head関数を使います。
# データの先頭5行をhead関数で表示する
df.head()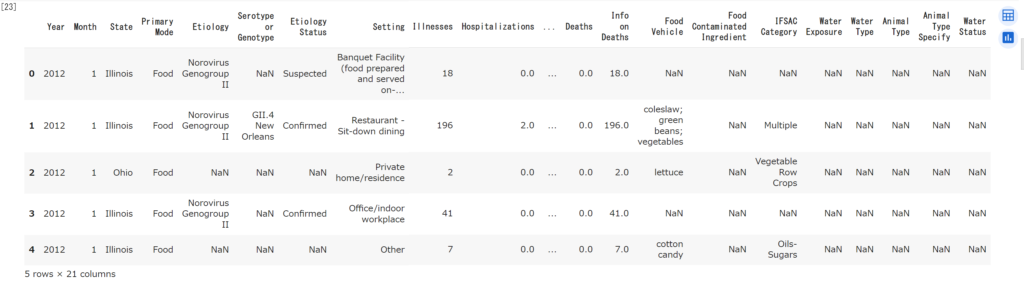
最初の5行だけが表示されました。一番上のYear、Month、State…が列名です。「Etiology」が食中毒の原因となった病原物質になります。
head関数が先頭5行を表示しました。最後の5行を表示する関数は想像できますか。head(頭)の反対の言葉です。
tail関数を使います。下のコードを実行すると、最後の5行が表示されますので、やってみてください。
# データの最後5つをtail関数で表示する
df.tail()各年の患者数と入院者数を表示する
このdfは10年間のデータであるため、各年度の患者数、入院者数を見てみましょう。
# それぞれの年度の患者数(Illnesses)、入院者数(Hospitalizations)を表示
df_year_grouped = df[['Year', 'Illnesses', 'Hospitalizations']].groupby(by = 'Year',as_index=False).sum()
df_year_grouped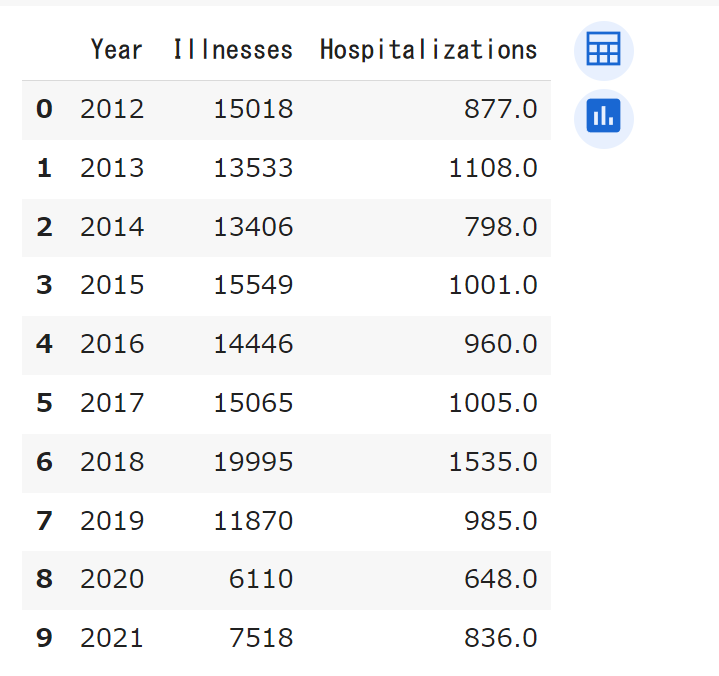
元のデータが、たった1行のコードで、各年度の患者数、入院者数の計算をすることができました。
ここでは「groupby」と「sum」関数を使ってい計算を行い、その結果を「df_year_grouped」という変数に格納しています。
エクセルでも同じことはできなくはないですが、すこし複雑になりますね。
groupby関数は「by=’ ‘」の値によりデータをグループ分けして、簡単に集計を行うことができます。
せっかくですから、この結果をグラフにしてみましょう。最初にインポートした「matplotlib」を使います。
# x軸とy軸を設定
X = df_year_grouped[['Year']]
Y1 = df_year_grouped[['Illnesses']]
Y2 = df_year_grouped[['Hospitalizations']]
# x軸のラベル
plt.xlabel("Year")
# グラフタイトル
plt.title('Number of Foodborne Illnesses and Hospitalizations in the U.S.')
# グラフのプロット(2つのグラフを区別のため「ラベル」を付与)
plt.plot(X, Y1, label='Illnesses')
plt.plot(X, Y2, label='Hospitalizations')
plt.legend() #凡例を表示
plt.show()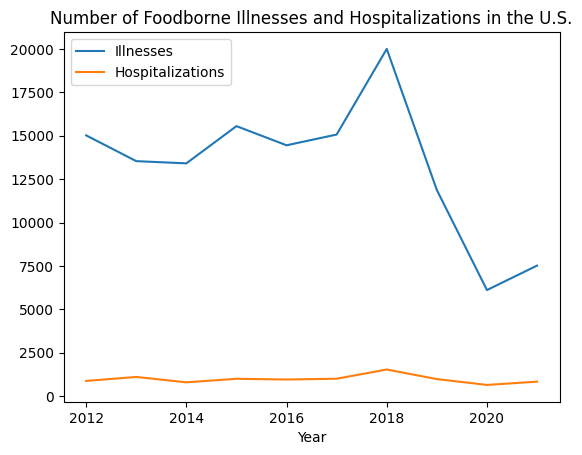
2018年には2万人近い患者がいたにもかかわらず、2020年には半分以下に減っていますね。この減少はCOVID-19の影響かもしれません。
それぞれの値をいじってみて、グラフがどのように変わるか確認してみてください。
州ごとの患者数を表示する
次は州ごとの患者数を計算してみましょう。
# 州ごとの患者数合計を計算
df_state_grouped = df[['State', 'Illnesses']].groupby(by = 'State',as_index=False).sum()
df_state_grouped.head()先ほどの各年の計算と同じで、groupbyとsum関数を使って、州ごとの患者数を計算しています。結果を「df_state_grouped」に格納し、head関数で先頭5行だけを表示しています。
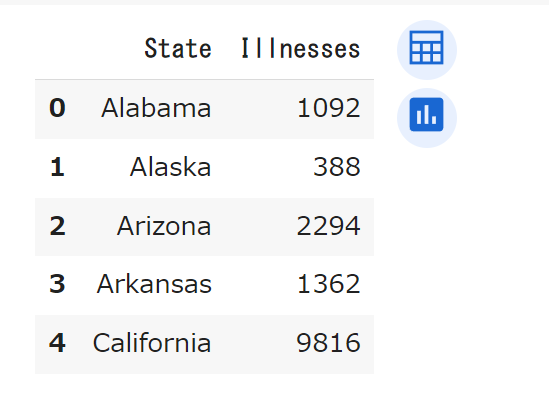
各州の患者数(Illnesses)がわかりました。ただし、この値は10年間分です。そのため、各値を10で割り、年平均を計算します。
# x軸とy軸を設定
df_state_grouped['Average_Illnesses'] = df_state_grouped['Illnesses'] / 10
df_state_grouped.head()=(イコール)の左側をdf_state_grouped[‘Average_Illnesses’]とすることで、新たに「Average_Illnesses」という列を作ることができます。値にはイコールの右側の計算結果が入ります。
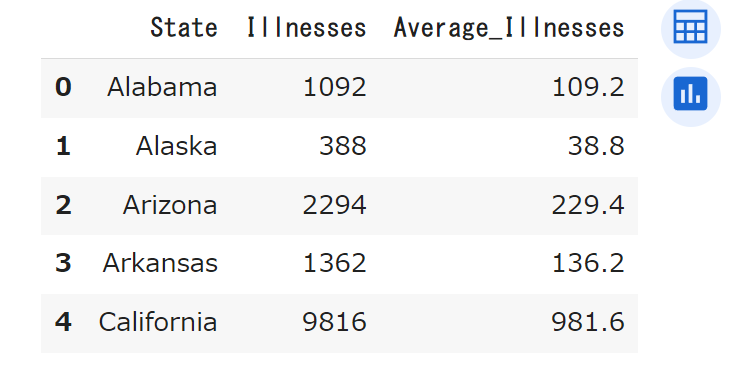
新たに「Average_Illnesses」の列が追加され、値を見ると、「Illnesses」の1/10になっていますね。
各州の人口データをロードする
これで、各州の食中毒患者の年平均が分かりました。しかし、各州の人口が異なるので、単純に比較することはできません。そこで、人口10万人あたりの食中毒患者数になるよう計算します。そのためには、まず各州の人口のデータが必要になります。
下にある「us-state-populations.zip」ファイルをダウンロードしてください。zipファイルに入っているので、すべて展開し、中にある「us-state-populations.csv」をGoogleドライブにアップロードしてください。アップロードのやり方はこちらの記事を参考にしてください。
アップロード後に、下のコードを実行します。すると、人口のデータが「us_pop」に格納されます。
# 各州の人口データをロードし、us_popに格納する
us_pop = pd.read_csv('us-state-populations.csv')
us_pop.head()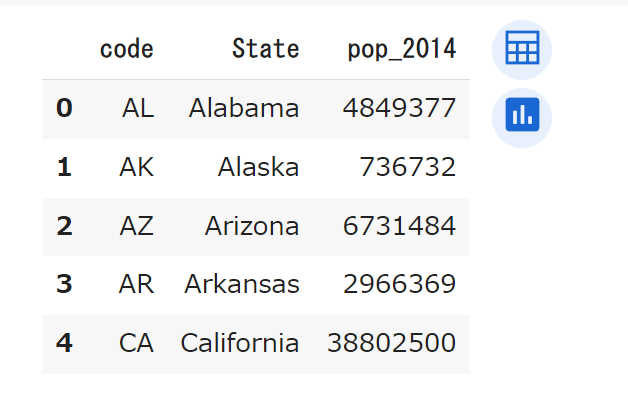
「pop_2014」が2014年の各州の人口になります。
食中毒患者数と人口のデータを結合する
次に「df_state_grouped」と「us_pop」のデータを結合し、一つにします。
# データを結合する
df_merged = pd.merge(df_state_grouped, us_pop, how = 'inner', on = 'State')
df_merged.head()Pandasのmerge関数を使い2つのデータフレームを結合します。その際、「on = ‘State’」とすることで、両方のデータにある同じ列名「State」を基準に、データを結合します。
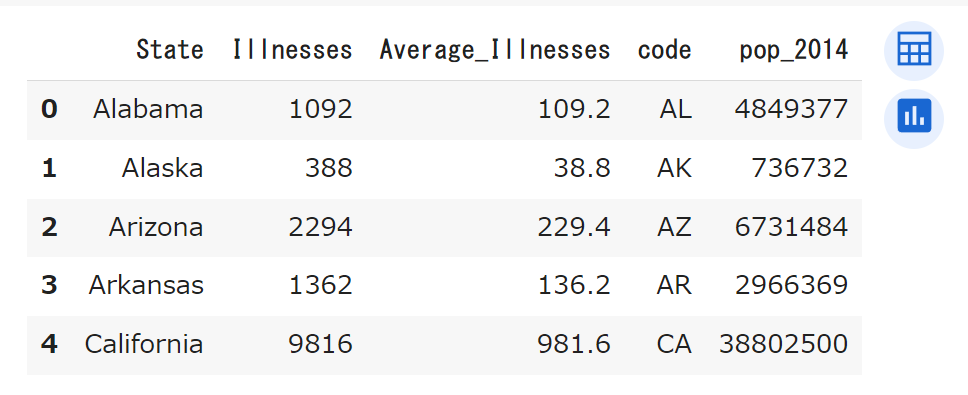
2つのデータが結合されました。1行のコードで簡単にできますね。
人口10万人あたりの食中毒患者数を計算する
ようやく人口10万人あたりの食中毒患者数を計算する準備が整いました。
下のセルでは、新しく「Illness_adjusted」の列を作り、そこに「平均食中毒患者数/人口」の結果を格納しています。
# 人口10万人あたりの食中毒患者数を計算し「Illness_adjusted」の列に格納する
df_merged['Illness_adjusted'] = df_merged['Average_Illnesses'] / df_merged['pop_2014'] * 100000
df_merged.head()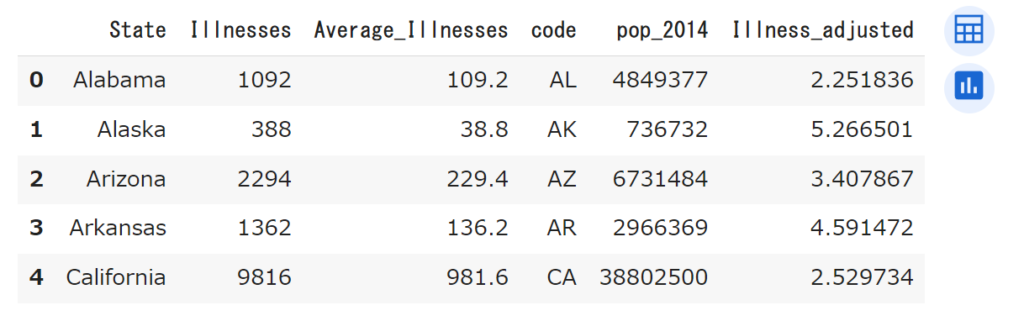
一番最後の列に「Illness_adjusted」が追加されました。これが各州の人口10万人あたりの食中毒患者数(10年間分を平均)になります。
10万人あたりの食中毒患者数をマッピングする
最後に各州の10万人あたりの食中毒患者数を地図にマッピングしてみましょう。マッピングには新たに「plotly」というライブラリを使います。
# plotlyライブラリを使って人口10万人あたりの食中毒患者数をマッピングする
import plotly.graph_objects as go
fig = go.Figure(data=go.Choropleth(
locations=df_merged['code'], # codeの列を使ってマップの位置を合わせる
z = df_merged['Illness_adjusted'].astype(float), # 「Illness_adjusted」の数値を使う
locationmode = 'USA-states', # plotlyに内蔵されているマップを使う
colorscale = 'Reds', # 赤色を使う
colorbar_title = "FP Illnesses/100,000", # 凡例のタイトル
))
fig.update_layout(
title_text = '2012-2021 average FP Illnesses by State', # マップのタイトル
geo_scope='usa', # limite map scope to USA
)
fig.show()右上のバーモント州が一番濃く(11.28人)、真ん中あたりのインディアナ州が一番薄いですね(0.78人)。
マップの各州の上をマウスオーバーすると、数値と州の略称が表示されます。マップの拡大縮小もマウスで簡単に行えます。「plotly」を使うと、このようなインタラクティブなマップを簡単に作ることができます。今回はあまり変数を指定せずに使用しましたが、細かく設定するとこのような様々なグラフが作れます。
また、グラフ描写のライブラリは今回使った「matplotlib」、「plotly」の他にもいろいろあります。自分のお気に入りのライブラリを見つけて、使ってみてください。
以上がデータ分析の実践編です。

今回使用したコードをすべて理解しなくて大丈夫です。なんとなく、こんなことをやっているんだな程度で理解してもらえればと思います。
大事なのは「実践」です。
今回使用したコードの値、変数の一部を変えてみて、どのようにグラフが変化するか、エラーが起きるか、などいろいろとやってみてください。







コメント