

食品安全分野で働く人であっても、デジタルリテラシー向上が必要な理由については、以下の記事をご覧ください。

Pythonの基本操作(ライブラリ編)については、以下の記事をご覧ください。


今回はPythonでデータ分析を行う上で、基本となる「データの型」について学んでいきます。
さらに、基本的なデータ型から発展して、データ分析に欠かせない「データフレーム」についても触れていきます。
「データの型」というのは、簡単に言うとデータの種類のことです。「3」は数値で、「Hello World」は文字列といった具合です。
Pythonには今まで学んだ数値、文字列の他にも様々なデータの型があります。

なぜデータの型をしっていなければいけないの?
特定のデータ型にしか使えない関数やルールがあるためです。つまり、データ型によってできること、できないことがあるということです。
そのため、データ型を理解しないでプログラミングを行っていると、多くのエラーが発生してしまい、行き詰ってしまう原因になります。

データ型を理解することで、スムーズにコードを書けるようになり、効率的にデータ分析が行えるようになります。
データ型の基本
データ型を確認するには「type関数」を使います。さっそくコードを見ていきましょう。
整数(int型)
下のコードでは、変数xに数値「3」を代入し、type関数でxのデータ型を確認しています。
x = 3
type(x)# 結果
int結果は「int」となりました。「int」はinteger(整数)を短くしたものです。
数値のデータ型にはこのint型に加え、次のfloat型というのがあります。
浮動小数点(float型)
次に変数xに「3.14」を代入し、type関数でxのデータ型を確認します。
x = 3.14
type(x)# 結果
float結果は「float」となりました。「float」は浮動小数点と呼ばれるデータ型で、小数点を含む数値を表す際に使われます。
文字列(str型)
変数yに「Hello World!」を代入し、type関数でyのデータ型を確認します。文字列をシングルクォート ‘…’で囲むのを忘れないでください。
y = 'Hello World!'
type(y)# 結果
str結果は「str」となりました。「str」はstring(文字列)を短くしたものです。
真偽値(bool型)
変数zに「True」を代入し、type関数でzのデータ型を確認します。
z = True
type(z)# 結果
bool結果は「bool」となりました。「bool」はBoolean(ブーリアン型:真偽値)を短くしたものです。
bool型は「真(True)」と「偽(Fales)」の2つの値をとるデータ型です。文字列ではないのでシングルクォート ‘…’で囲まないのも特徴です。(シングルクォートで囲むと文字列になります。)
条件分岐(例:結果が真ならAを行う。偽ならBを行う。)など、少し複雑なプログラミングを行う際によく使用します。
例えば以下のコードを実行すると、print(a)は「True」を返します。これは「10 > 5」が正しいのでTrueとなるわけです。
a = 10 > 5
print(a)# 結果
True逆にprint(b)は「False」を返します。これは「10 < 5」が正しくないためです。
b = 10 < 5
print(b)# 結果
Falseデータ型の応用編
ここからはデータ型の応用編に入っていきます。
リスト(list型)
今までのデータ型は1つの整数や1つの文字列といった形式でしたが、「リスト」は複数のデータを格納できるデータ型です。
リストの特徴として「整数と文字列」といった複数のデータ型を混ぜて格納することがでます。下の例では整数と文字列のデータを変数aに代入しています。
半角の角括弧 [ ] の中に値を入れ、それぞれの値をカンマ( , )で区切ります。カンマの後の半角スペースは、見やすくするためですので、なくても問題ありません。
a = [78, '不合格', 92, '合格']
type(a)# 結果
listリストの中の値には「インデックス番号」と呼ばれる順番が自動で振られます。そのため、インデックスの番号を指定すれば、リスト内の特定の要素にアクセスできます。具体的には、下のように変数[インデックス番号]で、該当する要素にアクセスできます。
a[1]# 結果
'不合格'結果を見て「おやっ!」と思ったのではないでしょうか。a[1]と1つ目の要素(80)を指定したのに、2つ目の要素(不合格)が表示されました。
実は、Pythonのインデックスの付け方はすこし変わっていて、1つ目の要素が0番目になります。

そのため、1つ目の要素にアクセスしたいときは、次のように[0]としなければなりません。
a[0]# 結果
78インデックスが0から始まるというのは、python独特のルールです。
Pythonの他のデータ型でも同じようにインデックスが0から振られるため、Pythonでプログラミングを行う際には、頭の切り替えが必要になります。
データフレーム(DataFrame)
データフレームの構造
データフレーム(DataFrame)は表のようなデータ形式です。2次元のデータに対応する構造で、行と列で表現されます。エクセルの表形式を思い浮かべるとイメージしやすいと思います。データ分析によく使われるデータ型です。
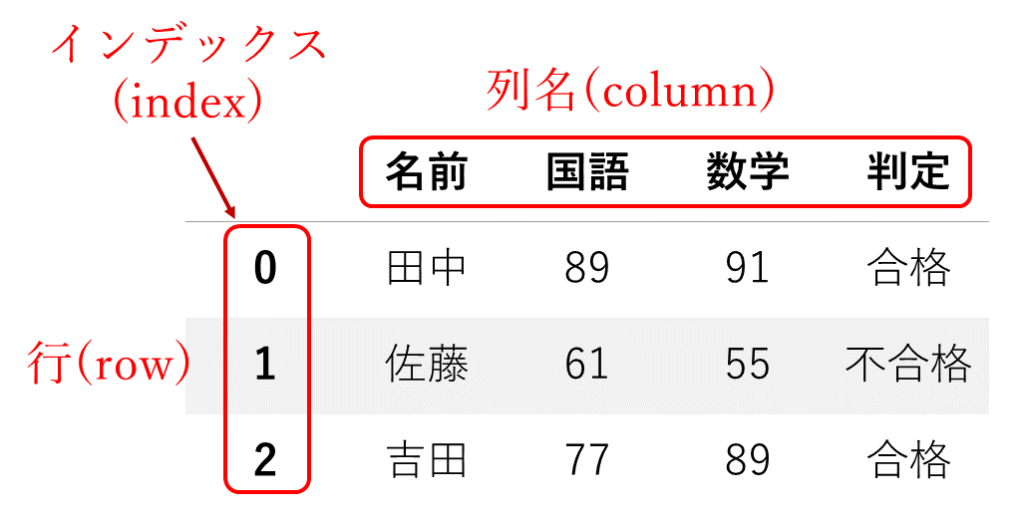
列(column)は縦に、行(row)は横にデータを見ていきます。言葉が似ているので、混同してしまいますが、大事な点なので正確に覚えましょう。覚え方はこちらの記事などを参考にしてください。
インデックスは、先ほどのリストと同様、0から振られます。
上の例では、0列目の「名前」という列には[‘田中’, ‘佐藤’, ‘吉田’]という値が入っています。0行目には[‘田中’, 89, 91, ‘合格’]という値が入っています。
データフレームの行や列の1つだけを取り出したものを「Series」といいます。データフレームにしか使えない関数、Seriesにしか使えない関数がありますので、この2つの言葉の違いも理解しておいてください。
データフレームを準備する
それでは、実際にPythonでデータフレームを見てみましょう。
下のコードをノートブックに入力し、実行してください。
# seabornをインポートし、その中にある「titanic」というデータをdfに代入
import seaborn as sns
df = sns.load_dataset('titanic')
df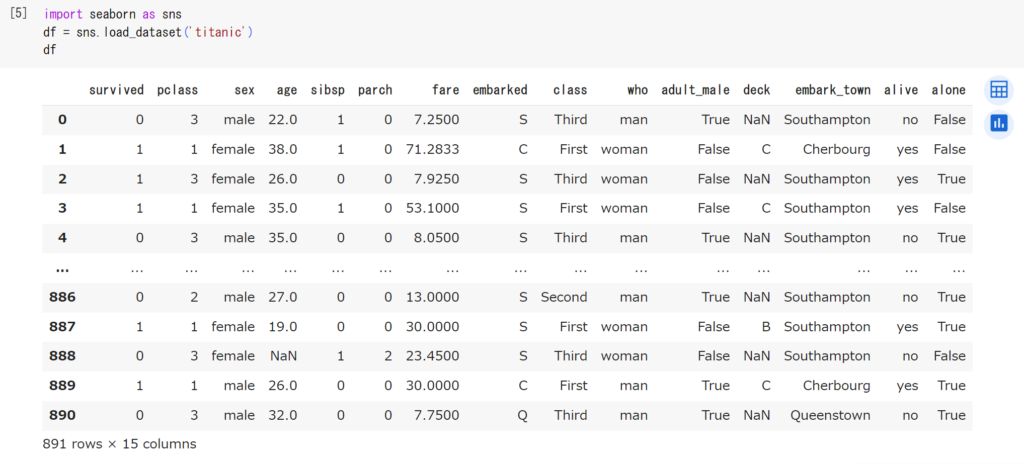
上のような表が表示されました。それぞれのコードの説明です。
- 「import seaborn as sns」では「seaborn」というライブラリを「sns」という別名でインポートしました。
- 「df = sns.load_dataset(‘titanic’)」では、「seaborn」ライブラリに含まれる「titanic」というデータをロードし、「df」という変数に入れました。(「df」はdataframeを短くしたものです。変数名は何でもよいのですが、データフレームを扱う時は「df」とすることが多いです。)
- 最後の「df」で、titanicのデータが入ったdfを表示しました。
つまり、seabornというライブラリに含まれている既存のデータ(titanic)をdfに入れ、dfを表示したということです。
Pythonでは、このように様々な練習用データがライブラリに含まれています。ちなみにseabornはデータを可視化する際に用いるライブラリです。
また、今回使用した「titanic」は、1912年に北大西洋で氷山に衝突して沈没したタイタニック号の乗客者の生存状況、名前、年齢、性別、経済状況などを含むデータです。データ分析や機械学習の練習によく使われます。

それでは、先ほど表示されたデータフレームの左下を見てください。「891 rows × 15 columns」と書いています。つまり、titanicというデータフレームは「891行 × 15列」あるということです。
また、上にある「survived、pclass、sex、age…」は列名です。
英語と日本語の違いはありますが、最初に見てもらったデータフレームの例と同じ作りになっているのが分かると思います。
特定の列や行、値の取り出し
それでは次に特定の行や列を選択する方法を見ていきます。
まずは、特定の列の抽出です。dfから「age」(年齢)の列だけを取り出してみましょう。
# dfからageの列を抽出
df['age']# 結果
0 22.0
1 38.0
2 26.0
3 35.0
4 35.0
...
886 27.0
887 19.0
888 NaN
889 26.0
890 32.0
Name: age, Length: 891, dtype: float64age列の値だけが取り出せました。
データフレームから列の1つだけを取り出したため、このデータ型は「Series」になります。ちなみに下のコードのようにageを囲う角括弧を2重にすると、データフレームとして値を取り出すこともできます。取り出した後に何をするのかによって、取り出し方法を使い分けます。
# dfからageの列を抽出(データフレームとして取り出し)
df[['age']]次に行を取り出してみましょう。
下のコードでは最初の3行を抽出しています。
# dfの最初の3行を抽出
df[0:3]
df[0:3]はdfの0~2行目という意味です。インデックスが0から始まるため[0: ]となっています。
また、「 :3」となっているのに、なぜ0, 1, 2, 3行目ではなく、0, 1, 2行目までが抽出されたのでしょうか。実はPythonのこのような抽出方法(スライスといいます。)を行う場合、下の図のような番号をイメージする必要があります。
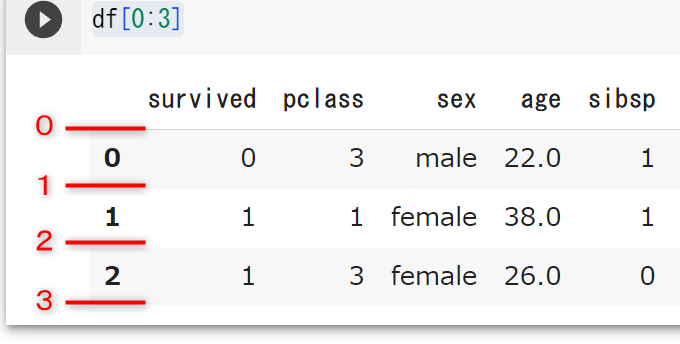
上の図で0~3の間にあるのは、0~2行目までですね。そのため、0, 1, 2行目だけが抽出されました。
独特で難しく感じるかもしれませんが、データ分析をする際にスライスはよく使うテクニックです。[ : ]で抽出する際には、[ : 1つ手前まで ]と覚えておいてください。
最後に特定の値を抽出します。
たとえば、男性だけを抽出したい場合、以下のようになります。
# dfから男性(male)のデータだけを抽出
df[df['sex'] == 'male']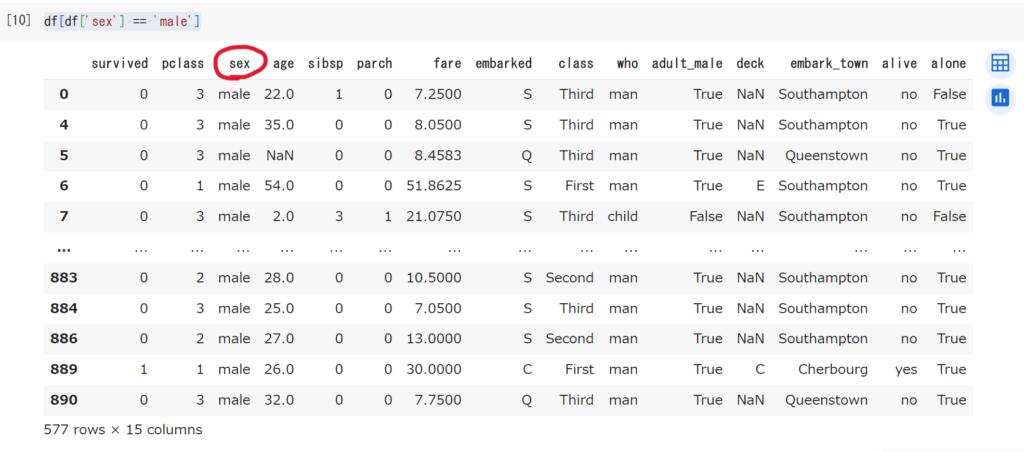
sexの列を見ると、maleだけしかありませんね。1行のシンプルなコードですが、カッコが多くて難しく感じるかもしれません。そういうときは分解して考えましょう。
まず df[‘sex’] で、dfのsexの列だけを抽出しています。
# dfのsexの列だけを抽出
df['sex']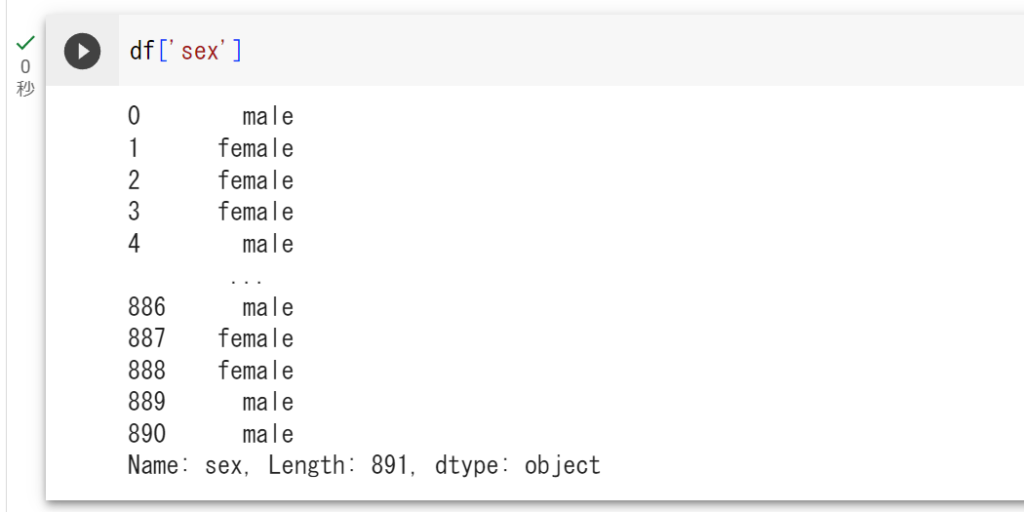
次に、「== ‘male’」となっています。「==」は比較演算子と呼ばれるものです。「a == b」の場合、aとb が等しいときは「True」を、等しくないときは「False」を返します。
# sexの列のうちmaleかどうかを判別
df['sex'] == 'male'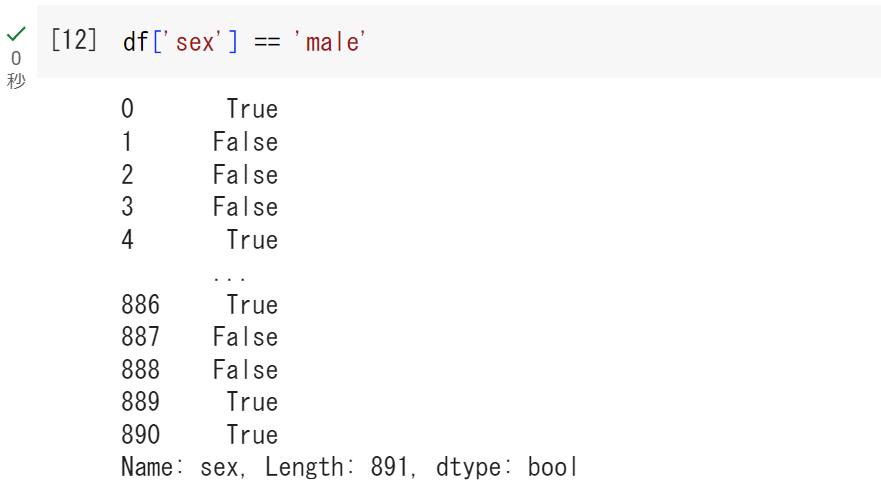
maleのときは「True」、femaleのときは「False」となっているのがわかるでしょうか。
最後にこの結果をdf[ ]で囲っています。これにより、Trueとなった行だけを抽出することができます。
# dfから男性(male)のデータだけを抽出
df[df['sex'] == 'male']考え方は理解できたでしょうか。実際に抽出するときには、こんな細かいことは考えず、コードをコピーし、必要な箇所だけ変更すれば大丈夫です。
# dfの女性(female)のデータだけを抽出
df[df['sex'] == 'female']
# dfの生存者(survivedが1)のデータだけを抽出
df[df['survived'] == 1]
# dfの年齢が30歳以上のデータだけを抽出
df[df['age'] >= 30]以上がデータ型の解説です。
実はここで紹介したデータ型以外にも、様々なデータ型があります。
(例)datetime(日付型)、dictionary(辞書型)、tuple(タプル型)
全部は解説できないため、今回はデータ分析に必須となるデータ型だけを紹介しました。もし、新しいデータ型に出会った際には、その都度インターネットで調べてみてください。
また、データフレームから行、列、値の抽出方法をいくつか紹介しました。ここで紹介した抽出方法以外にも、多くの方法があります。自分がやりやすい方法で抽出すればよいので、「python データフレーム 列の抽出」など、いろいろ調べて試してみて下さい。







コメント